








Кодирование символов
Общий подход
Поскольку в современных компьютерах информация всех видов представлена в двоичном коде, нужно разобраться, как закодировать символы в виде цепочек нулей и единиц. Например, можно предложить способ, основанный на системе Брайля для незрячих людей, о которой мы уже упоминали (см. задачу 17 на стр. 66). В нём каждый символ кодируется с помощью 6 точек, расположенных в два столбца. В каждой точке может быть выпуклость, которая чувствуется на ощупь. Обозначив выпуклость единицей, а её отсутствие нулём, можно закодировать первые буквы русского алфавита следующим образом:
10 100000 00 00 0 1 011101 11 01 - A
10 101000 10 1 1 111100 11 00 - Б
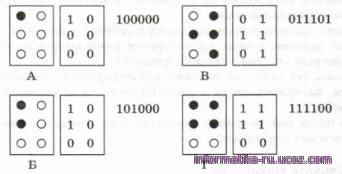
Здесь двоичный код строится так: строки полученной таблицы, состоящей из цифр 0 и 1, выписываются одна за другой в строчку. Так как используются всего 6 точек, количество символов, которые можно закодировать, равно 26 - 64 (в реальной системе Брайля 63 символа, потому что символ, в коде которого нет ни одной выпуклости, невозможно обнаружить на ощупь). Понятно, что совершенно не обязательно использовать код Брайля. Главное каждому используемому символу как-то сопоставить цепочку нулей и единиц, например составить таблицу «символ - код». На практике поступают следующим образом:
1) определяют, сколько символов нужно использовать (обозначим это число через );
2) определяют нужное количество к двоичных разрядов так, что- бы с их помощью можно было закодировать не менее и разных последовательностей (т. е. 2* ≥ );
3) составляют таблицу, в которой каждому символу сопоставляют код (номер) целое число в интервале от 0 до 2 - 1;
4) коды символов переводят в двоичную систему счисления.
В текстовых файлах (которые не содержат оформления, например, в файлах с расширением txt) хранятся не изображения символов, а их коды. Откуда же компьютер берет изображения символов, когда выводит текст на экран? Оказывается, при этом с диска загружается шрифтовой файл (он может иметь, например, расширение fon, ttf, otf), в котором хранятся изображения, соответствующие кодам 1. Именно эти изображения и выводятся на экран. Это значит, что при изменении шрифта текст, показанный на экране, может выглядеть совсем по-другому. Например, многие шрифты не содержат изображений русских букв. Поэтому, когда вы передаёте (или пересылаете) кому-то текстовый файл, нужно убедиться, что у адресата есть использованный вами шрифт. Современные текстовые процессоры умеют внедрять шрифты в файл; в этом случае файл содержит не только коды символов, но и шрифтовые файлы. Хотя файл увеличивается в объёме, адресат гарантированно увидит его в таком же виде, что и вы.
Кодировка АЅСII и её расширения
Для того чтобы упростить передачу текстовой информации, разработаны стандарты, которые закрепляют определённые коды за общеупотребительными символами. Основным международным стандартом является 7-битная кодировка ASCII (англ. American Standard Code for Information Interchange американский стандартный код для обмена информацией), в которую входят 27 128 символов с кодами от 0 до 127:
• служебные (управляющие) символы с кодами от 0 до 31; • символ «пробел» с кодом 32;
• цифры от «0» до «9» с кодами от 48 до 57;
• латинские буквы: заглавные, от «А» до «Z» (с кодами от 65 до 90) и строчные, от «а» до «Z» (с кодами от 97 до 122);
• знаки препинания::; 12
• скобки: [[ 0
• математические символы: + - * /=<>
• некоторые другие знаки: # $ % & @\_~
В современных компьютерах минимальная единица памяти, имеющая собственный адрес, это байт (8 битов). Поэтому для хранения кодов ASCII в памяти можно добавить к ним ещё один (старший) нулевой бит, таким образом, получая 8-битную кодировку. Кроме того, дополнительный бит можно использовать: он даёт возможность добавить в таблицу еще 128 символов с кодами от 128 до 255. Такое расширение ASCII часто называют кодовой страницей. Первую половину кодовой страницы (коды от 0 до 127) занимает стандартная таблица АЅСІІ, а вторую - символы национальных алфавитов (например, русские буквы):

Кодовая страница
Для русского языка существуют несколько кодовых страниц, которые были разработаны для разных операционных систем. Наиболее известны:
- кодовая страница Windows-1251 (CP-1251) - в системе Windows;
- кодовая страница КО18-R - в системе Unix;
- альтернативная кодировка (СР-866) - в системе МЅ DOS;
- кодовая страница MacCyrillic - на компьютерах фирмы Apple (Макинтош и др.).
.Проблема состоит в том, что, если набрать русский текст в од ной кодировке (например, в Windows-1251), а просматривать в другой (например, в KOI8-R), текст будет невозможно прочитать:
Windows-12518
Привет, Вася!
KO18-R
ПХБЕР, БЮЯъ! Привет, Вася!
РТИЧЕФ, чБУС!

Для веб-страниц в Интернете часто используют кодировки Windows-1251 и KO18-R. Браузер после загрузки страницы пытается автоматически определить ее кодировку. Если ему это не удаётся, вы видите странный набор букв вместо понятного русского текста. В этом случае нужно сменить кодировку вручную с помощью меню Вид браузера.
Стандарт UNICODE
Любая 8-битная кодовая страница имеет серьёзное ограничение - она может включать только 256 символов. Поэтому не получится набрать в одном документе часть текста на русском языке, а часть - на китайском. Кроме того, существует проблема чтения документов, набранных с использованием другой кодовой страницы. Всё это привело к принятию в 1991 г. нового стандарта кодирования символов UNICODE, который позволяет записывать знаки любых существующих (и даже некоторых «мёртвых») языков, математические и музыкальные символы и др.
Если мы хотим расширить количество используемых знаков, необходимо увеличивать место, которое отводится под каждый символ. Вы знаете, что компьютер работает сразу с одним или несколькими байтами, прочитанными из памяти. Например, если увеличить место, отводимое на каждый символ, до двух байтов, то можно закодировать 216 65 536 символов в одном наборе. В современной версии UNICODE можно кодировать до 1 112 064 различных знаков, однако реально используются немногим более 100 000 символов.
В системе Windows используется кодировка UNICODE, называемая UTF-16 (от англ. UNICODE Transformation Format формат преобразования UNICODE). В ней все наиболее важные символы кодируются с помощью 16 битов (2 байтов), а редко используемые - с помощью 4 байтов.
В Unix-подобных системах, например в Linux, чаще применяют кодировку UTF-8. В ней все символы, входящие в таблицу АЅСІІ, кодируются в виде 1 байта, а другие символы могут занимать от 2 до 4 байтов. Если значительную часть текста составляют латинские буквы и цифры, такой подход позволяет значительно уменьшить объём файла по сравнению с UTF-16. Текст, состоящий только из символов таблицы AЅСІІ, кодируется точно так же, как и в кодировке ASCII. По данным поисковой системы Google, на начало 2010 г. около 50% сайтов в Интернете использовали кодировку UTF-8.
Кодировки стандарта UNICODE позволяют использовать символы разных языков в одном документе. За это приходится «расплачиваться» увеличением объёма файлов.